What is a Scenario?
A Scenario is a single, self-contained test case or task where an agent is given a problem and is expected to modify a target environment to solve it. Scenarios are the building blocks of both Public Benchmarks and Custom Benchmarks. Each Scenario includes:- Problem Statement: The task description your agent will work on.
- Environment: A devbox environment (from a blueprint or snapshot) that contains all required code and tools.
- Scorer: One or more scoring functions that determine whether the agent succeeded and emit a score between 0.0 and 1.0.
- Reference Output: A canonical solution or patch used to validate the scorer. After applying the reference output to the environment, the scorer should emit a score of 1.0.
Creating Scenarios
Creating a Scenario from scratch involves the following high-levelworkflow steps:
1. Environment setup
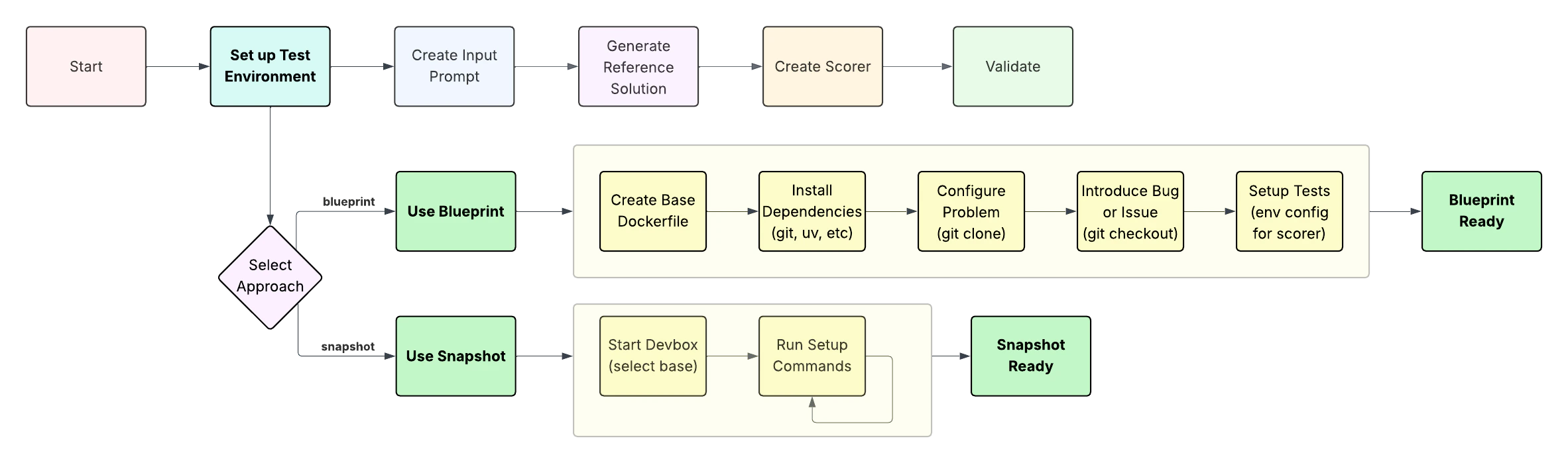
2. Configure scoring and reference output
Next, define how success is measured and establish a reference output to validate that your scorer is working as expected. You can either use simple bash-based scorers or more advanced custom scorers using python or typescript. Developing a custom scorer is a powerful way to test a specific behavior or edge case and is often an iterative process.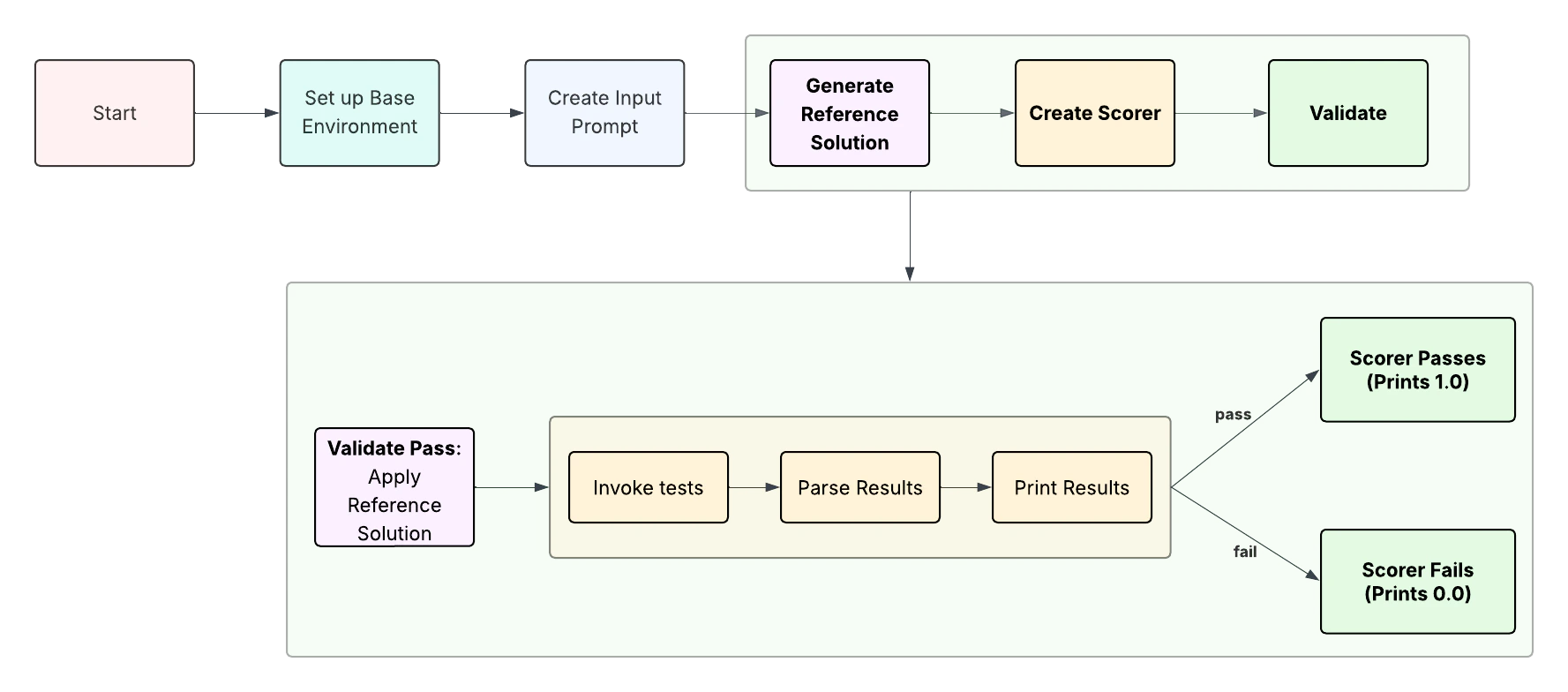
- Scoring functions: Add one or more scorers that return a score between
0.0and1.0. The script is kept outside of the devbox until scoring begins to avoid leaking solutions. - Weights: Combine multiple scorers by assigning weights to each component that add up to
1.0. - Reference Output (Optional): Provide a known-good output (such as a patch or command) that your scorer can compare against. The reference solution is kept outside of the devbox to avoid leaking solutions.
3. Add to Benchmarks
Once saved, your Scenario can be reused within multiple benchmarks or as a standalone run. You can also add metadata to organize Scenarios by purpose, difficulty, or use case.Scenario Execution Lifecycle
When you run a Scenario, Runloop manages the lifecycle of the devbox and the scoring process. The execution flow is the same whether you use orchestrated or interactive mode.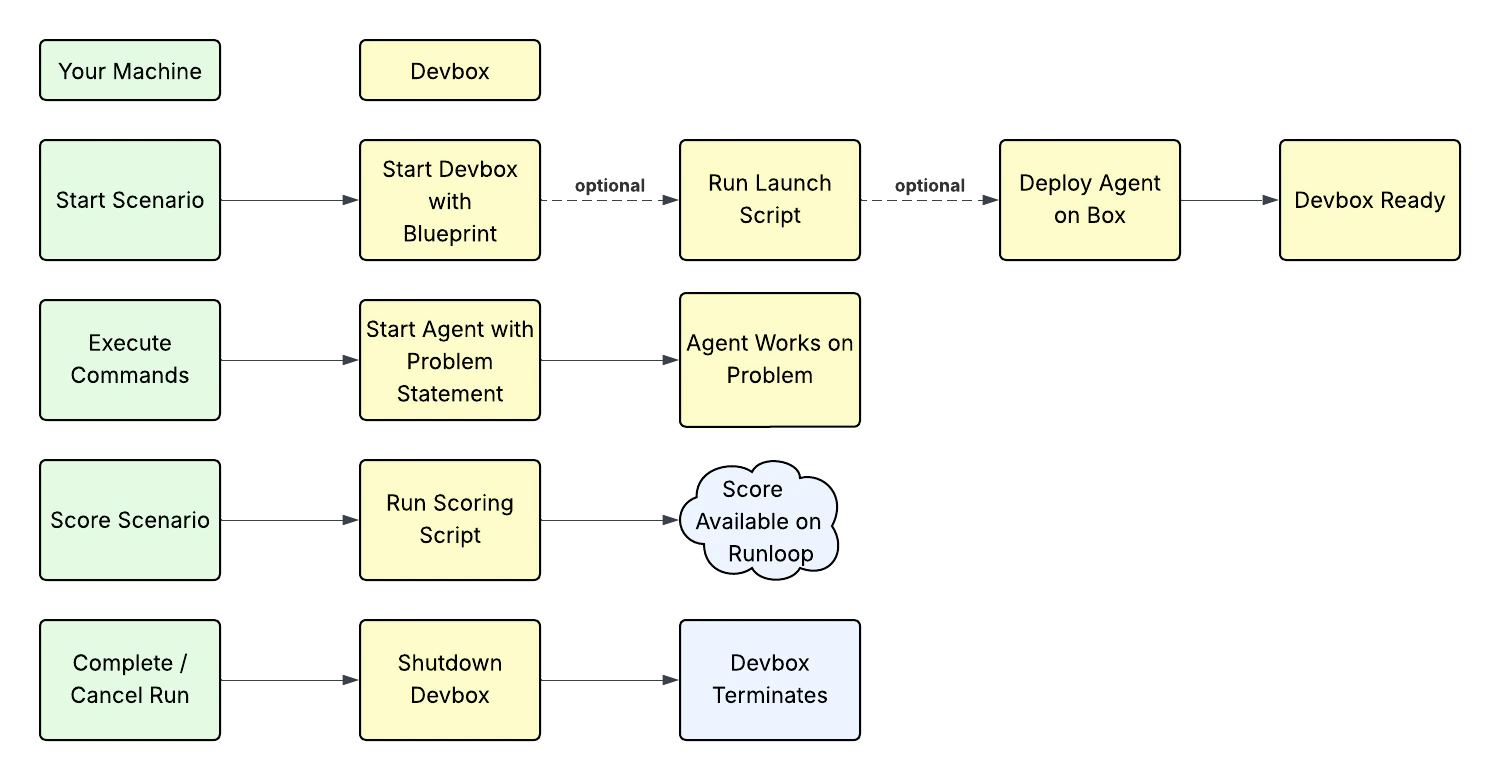
- Run created: A Scenario run record is created to track execution.
- Environment Provisioning: Runloop launches a devbox using the Scenario’s environment configuration and runs any launch scripts or commands.
- Agent Mounting (Optional): Your agent is deployed onto the devbox.
- Run Execution: Execute arbitrary commands on the devbox. Most commonly, you will want to instruct the agent to work on the problem statement. The agent is expected to modify the environment to solve the problem.
- Scoring: The configured scoring functions run and produce a score between 0.0 and 1.0.
- Completion & reporting: The run is marked complete and results, logs, and traces are available in the dashboard and via API.
- Shutdown: The devbox is shut down and any resources are freed.
In orchestrated mode, Runloop handles all these phases automatically. In
interactive mode, you control each step of the execution process
programmatically via the SDK.
Creating and Running Scenarios via the API
Once you are comfortable with the dashboard workflow, you can automate Scenario creation and execution using the Runloop API. Here’s an end-to-end example that:- Creates an environment snapshot.
- Creates a Scenario.
- Starts and scores a Scenario run.